JPEG Image Compression: What you don't see (pt. II)

Everyone needs highly optimized images. Less file size, same visual qulaity. You can do it here at Compressman, but along the way we continue to learn more about JPEG Image Compression algorithm.
The way JPEG image compression does its magic is interesting and useful to know. It all thanks to image optimization algorithms that you can reduce image size without loosing the visual quality. Last time we started to look deeper into JPEG image compression methods. In this era of endless sequels to everything - we present you part II of our journey.
Quantization in Image Compression
Let's get right to it: the coefficients of Fw,u, are real numbers. These numbers will be saved as integers. The number we will get eventually is big anyway, so it mught cause minor problems. The solution is to round the coefficients; as we'll see, we do this in a way that makes it easier to make even greater compression.
But the rounding of integer is not as simple as it sounds. The easy way is to, y'a know, round up the digit or round it down. Insteadm we gonna divide the coefficient by a quantizing factor and then write down following:
round(Fw,u / Qw,u)
Here is a graph of alpha function as a function of q:

Take a closer look and yoi will see something interesting. Did you get it? Higher values of q give lower values of alpha function. We then round the weights as
round(Fw,u / a Qw,u)
The integer rounding means making the actual number lesser or bigger that in was originally. Yes, we will get a round and clean, awesome-looking digit (wich in the end is good for image compression), but there is a price to pay. During the process of rounding we will lost some data. When either alpha function or Qw,u is increased (do not forget that large values of alpha function correlate to smaller values of the quality parameter q), much more information is lost (hello, image compression!), and the file size,obviously, decreases. Kinda what we really wanted in the beginning of all that.
Calculating The Best of Image Compression
There is no need to calculate best luminance and/or chrominance values by yourself. The JPEG standard suggests and recommends them for you. Take a look at standard values for Qw,u - first, for the luminance coefficients and then for the chrominance coefficients:


The JPEG standard chooses these numbers to underline the lower frequencies. OK, now it's time to find out how these math mumbo-jumbo works for our blok image. Do you still remember it? Here it is:



Let's assume, that quantization with q = 50 gives the next blocks:



The number in the upper left corner - all it does it represents the average over the whole entire block during the process of image compression. Let's move to the right - we will see the increase of the horizontal frequency. If we go down - we will face the increase of the vertical frequency. Sounds good, lookd clean, what is next? Not so fast - there is something important to know here. Did you notices that there a lof, a lot of zeroes here? We now order the coefficients in a specific way so that the lower frequencies appear first. Take a closer look:

Let's take one example. For the luminance coefficients we record like this:
20 -7 1 -1 0 -1 1 0 0 0 0 0 0 0 -2 1 1 0 0 0 0 ... 0
Reconstructing and Optimizing the Image
Truly, a lot of zeroes. Can we get rid of them? Sure. Instead of recording all the zeroes, we can simply say how many of them actually appear. By the way, did you noticed that there are even more zeroes in the chrominance weights?. In this way, the sequences of DCT coefficients are greatly shortened. And THIS is the true goal of any compression algorithm! We will say even more - the JPEG algorithm uses extremely efficient methods to code data like this.
When we reconstruct back the DCT coefficients, we find that reconstructing the image from the data is pretty simple and straightforward. The quantization matrices are saved in the file during image compression process. Which means that approximate values of the DCT coefficients may be recalculated. From here, the (Y, Cb, Cr) vector is found through the Inverse Discrete Cosine Transform. Then the (R, G, B) vector is recreated by reversing the color space transform process.
Take a closer look at the reconstruction of the 8 by 8 block (second image) and compare it to the original. In this case the parameter q is set to 50 and to 10 (third image):


The Golden Standard of JPEG 2000
So, we saw that the JPEG image compression algorithm is quite successful when you want to get the best of image compression. Although, there are some factors that created the need for a new image compression algorithm. Let's talk about to of them.
So, the JPEG algorithm's use of the DCT leads to discontinuities at the edges of the 8 by 8 blocks. For example, the color of a pixel on the edge of a block can be manipulated by that of a pixel anywhere in the block. But not by an adjacent pixel in another block. This leads to blocking artifacts shown by the version of our image that was created with the quality parameter q set to 5 (by the way, the size of this image file is only 1702 bytes), This explains why JPEG is not an ideal format for saving and keeping a piece of line art.

Let's also add that the JPEG algorithm as it is allows us to recreate the image at only one resolution. Well, not the best news, huh? In some specific cases, it is strongly desirable to also recover the original image at lower or even higher resolutions. For example, it maight be handy when wee need to display the image at progressively higher resolutions while the full image is being downloaded as a background process.
Meet the Wavelet Transforms
This is one of many reasons why the JPEG 2000 standard was introduced in December 2000 - to address these demands, among others. While there are some - one or two, maybe more - differences between these two algorithms, we will concentrate on the simple fact that JPEG 2000 uses a wavelet transform instead of the DCT. Sounds new?
Yes, it does indeed, but before we explain the wavelet transform that we use in JPEG 2000 Image Compression Algorithm, we will consider a much more simple example of a wavelet transform. Once again, we will imagine that we are working with luminance-chrominance values for each and every pixel. The DCT works by applying the transform to one row at a time, then transforming the columns. The wavelet transform will work in a quiete similar way.
So by now, let's say that we have a sequence of f0, f1, ..., fn that describs the values of one of the three variables in a whole row of pixels. Once again, we wish to separate quick changes in the sequence from much more slow changes. So by now, we create a sequence of wavelet coefficients:

Did you noticed that the even coefficients write down the average of two successive values? We call this the low pass band. That is because information about high frequency changes is lost. So, while the odd coefficients write down the difference in two successive numbers - we call this the high pass band. That is because high frequency information is passed on. The number of low pass coefficients is half the number of values in the original sequence (as is the number of high pass coefficients).
Also, remember this: we may recreate the original f values from the wavelet coefficients. Like when we will need to do when reconstructing the image. Also, please consider watching this lecture about wavelet transforms. It is a long video, but a very good one:
Importance of Order in Image Compression
We change the placement and order of the wavelet coefficients by writing down the low pass coefficients first. Then the high pass coefficients follow right away. Just like as with the 2-dimensional DCT, now we can apply the very same same operation to transform the wavelet coefficients vertically. The result is this: a 2-dimensional grid of wavelet coefficients divided into four blocks by the low and high pass bands.
Once again, we know and use the fact that the human eye is much more less sensitive to quick variations to deemphasize the quick changes seen with the high pass coefficients wuth a quantization process analagous to one that was seen in the JPEG algorithm. Notice that the LL region is obtained by averaging the values in a 2 by 2 block and so id does indeed represents a lower resolution version of the image.
In reality, our image is divided into tiles. One tiles's size usually is of size 64 by 64. Why a power of 2, yoi might ask? Patience, padawan, patience. We will tell you and explain the reason for choosing a power of 2 soon enough. We will show it using our image with the tile indicated. (This tile is 128 by 128 so that it may be more easily seen on this page.)


Unique Abilities of JPEG 2000 Algorithm
Did you noticed that, if we transform the coefficients in the LL region first, we could recreate the image at a much more lower resolution before all the coefficients had come together at once. And this is one of many aims of the JPEG 2000 algorithm - and one of the most important for sure.
We may now start the very same process on the lower resolution image in the LL region. This will lead us to obtaining images of lower and lower resolution.



The wavelet coefficients may be calculated with a lifting process just like this:
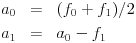
Looks interesting, right? There is something unique to this. The advantage here is that the coefficients may be calculated without using additional computer memory - a0 first replaces f0 and then a1 replaces f1. Let us also add that in the wavelet transforms - JPEG 2000 algorithm uses them, of course - the lifting process enables much more faster calculation of the coefficients than usual.
The JPEG 2000 Wavelet transform
We have already discussed and described the wavelet transformabove. Although similar in spirit, is simpler than the ones proposed in the good ol' JPEG 2000 standard. For example, it is really desirable to make an average over more than two successive values to obtain much more greater continuity in the recreated image and with that to avoid phenomena like some blocking artifacts. No one needs some blocking artifacts, right?! One of the wavelet transforms used is the Le Gall (5,3) spline in which the low pass (even) and high pass (odd) coefficients are computed by

Once again, this transform is invertible. We cannot get it back, it will be right the way it is. And there is a lifting scheme for making it efficiently - even much more efficient, we would dare to say. Another one of these wavelet transforms that are included in the standard is the Cohen-Daubechies-Fauraue 9/7 biorthogonal transform, whose details are a bit more complicated to describe, although a simple lifting recipe exists to use it in the right and useful way.
JPEG vs. JPEG 2000 - who's better?
It is really very good to compare JPEG and JPEG 2000. Let us say, that generally the two algorithms have similar compression ratios. Though JPEG 2000 requires much more computational effort to reconstruct the image than it's competitor. JPEG 2000 images do not show the blocking artifacts that are present in many forms in JPEG images at high compression ratios. But instead they become more blurred with much more increased image compression value. JPEG 2000 images are often judged by humans to be of a higher visual quality. Silly humans, what do they know, right.... Right?!
So right now, JPEG 2000 is not really widely supported by all web browsers but is used in digital cameras and medical imagery. There is also a related standard, Motion JPEG 2000. They use it in the digital film industry.
So, here you are, at the end of our two-part adventure into the wilds of JPEG Image Compression details. See you next time!
End of part II. See Part I.




